
Concept explainers
a.
To give and efficient
a.
Explanation of Solution
String matching based on repetition factors:
String matching is the method of finding some particular pattern in the whole string. There are two things one is pattern and one is whole string. The string matching refers to just check whether the given pattern is present in the string or not also to find out the position of the first letter of the patter till the length of the pattern. It may be in form of sequence or tree structures.
Suppose the input is a pattern
The first approach is the Naïve Approach.
The algorithm is given below:
3 for
add-result
6\}
The running of the algorithm would be
b.
To prove that the expected value of
b.
Explanation of Solution
Taking the pattern
Taking the pattern involving one string: xor y
When matching the above pattern, it iterates in one cycle maximum.
Taking the pattern involving two strings:
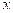 | 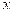 | or | 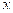 | 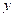 | or | 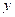 | 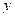 |
When trying to match the given string with the above pattern. It will match the string as single one or the text as a two together completing it in maximum one or two iteration.
Taking the pattern of three strings:
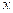 | 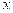 |  |
Again, while trying to match the above string either it matches a single string or a few strings together or all might be same.
Similarly, it can be done so for mstrings . Each time involving
c.
To argue that the string matching algorithm correctly find all occurrences of the patternP in a text
c.
Explanation of Solution
The given Galil-Seiferas algorithm consists of preprocessing phase and searching phase.The preprocessing phase of Galil-Seiferas algorithm involves finding decompositionab of x followingb that has at least one prefix period and
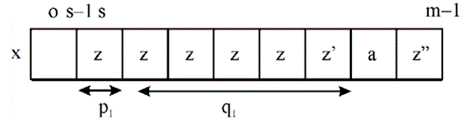
While searching for
- If
- Each time the mismatch occurs with
The preprocessing will incur
Want to see more full solutions like this?


- Let BStr be the set of all binary strings. Recall that N-0.12.) is the set of all natural numbers. Define a function q: BStr → N g(s) (the number of times the substring "01" occurs in s) Prove that q is onto. If you'd like to type your answer here, you may find the following symbols useful for copying and pasting: NZQREE E √arrow_forwardThe intersection of two sets contains the list of elements that are common to both, without repetition. As such, you are required to write an algorithm that finds and returns the intersection of two sets A and B. The sets A and B and the resulting intersection set are all lists. Assume the size of A is n and that of B is m. (a) Write an iterative algorithm that finds the intersection. (b) Prove the correctness of your algorithm; i.e. state its loop invariant and prove it by induc- tion. (c) Analyze the time complexity of your algorithm. (d) Think of a way to enhance the complexity of your algorithm by sorting both lists A and B before calculating their intersection. Write the enhanced version and prove that it has a better time complexity.arrow_forwardA string w of a's and b's is valid if it satisfies one of the following conditions: • w is the empty string • w = aub for some valid string u • w = uv for some valid strings u and v For example, the string w = aaabbabbaabbab is valid, because w : = uv, where u = aaabbabb and v= aabbab. Describe an efficient algorithm to determine whether a given string of a's and b's is valid. Analyze its time and space requirements. (Aim for solving the problem in linear time.) Show how the algorithm works on the above example.arrow_forward
- Let I be the set of strings (N, w) where N is an NFA that accepts the string w. Pick all that apply. L is decidable L recognisable. None of the above.arrow_forwardWe consider certain strings of length 6 over the alphabet S = {A,B,C}. We require that the string contains exactly two As, and exactly two B's, and exactly two C's. How many such strings are there? That is, how many strings of length 6 over the alphabet {A,B,C} contains exactly two A's, two B's and two C's?arrow_forwardOptional: Wiener's attack against d < N¹/4 1. Implement the Extended Euclidean algorithm to compute a sequence of integers ai, bį such that aį · u = bi (mod e), given as input u and e. 3 2. Write a function that given e, generates u = b/a (mod e) with gcd(a, e) = 1, gcd(a, b) = 1, 0 ≤ a < e¹/4 and 0 ≤ b < e³/4/2 3. Modify the Extended Euclidean algorithm to recover a, b given u and e. 4. Let N = 10130504119574269789293062680493199194915552096732359153857412158756437203 47135740015147283114417898552525558307523182360246570149631744078935953061839 8999802968854212580408518026278696751955766440302916899698207562116802903505 967192902681681626273432110182016329136690925805959479917572582616951641454736961 be an RSA modulus, and e = 3134657917572805640643483213467129157665628760339358509398392813132282456358 9978332807232269972876643175705237878721777376331255131580937895216938815784334 7877922918358552412126143406736881542173183213899346722202070378656735309988244…arrow_forward
- 1. Analyze the word finder with wild card characters scenario to form the algorithm and compute the time complexity. You are given a list of characters with size n, m. You need to read character data provided as input into this list. There is also a list of p words that you need to find in the given problem. You can only search in left, right, up and down direction from a position. There are two wild characters *' and '+' ,if there is any instance of wild card characters for example '+' appears you can match whatever character in your word that you are searching at this position (only one character). Similarly, if you got wildcard *' you can skip any number of characters ( A sequence of characters not necessary same in between the characters) but the last character should be matched in the given data. This means you are not allowed to match a first and last character with *' wildeard. Input: The first line of the input will give you two integers n and m. From the next line you will get…arrow_forwardConsider the searching problem:Input: A sequence of n numbers A = (a1, a2, a3, ….., an ) a value V.Output: An index i such that v = A[i] or the special value NIL if v does not appear in A.Write pseudocode for linear search, which scans through the sequence, looking for v. Using a loop invariant, prove that your algorithm is correct. Make sure that your loop invariant fulfills the three necessary propertiearrow_forward2. Let n be a positive integer, and let A be a list of positive integers. We say that the integer n can be factorized by A if there exists a sequence of integers 11, 12,..., ik (with 0 ≤i; < len (A), for j = 1,..., k) such that n is the product of the integers A[i], A[i2],..., A[ik]. Write an efficient algorithm factorizable (n, A) that returns True if n can be factorized by A, and False otherwise. Prove that your algorithm is correct, and bound its running time. Larger scores will be awarded to faster solutions. Example 1: if n = 6 and A [4,2,3], then factorizable (n, A) should return True, L[1] * L[2]. since n == Example 2: if n = 8 and A = L[0] * L[0] * L[0]. [2,5], then factorizable (n, A) should return True, since ,2,3,5,7], then factorizable (n, A) should return Example 3: if n = 13 and A = False since n cannot be factorized by A.arrow_forward
- Write an algorithm for addressing the subset-superset problem in string matching. That is, search a text with several strings, some of which are factors of others. do not return any strings that are factors of other test strings found in text (b) Repeat with text consisting of 100 appended copies of and the test itemsarrow_forwardAlgorithm of Preis in AlgebraThe following steps make up the algorithm.A weighted graph G = as the first input (V, E, w)A maximum weighted matching M of G as the output.While E =, choose any v V at random, let e E be the largest edge incident to v, and then perform the following calculations: 3. M e; 4. E e; 5. V V; 6.11. Two different Python implementations of this algorithm are shown by E, E, and all edges that are adjacent to e.arrow_forwardPlease help me fill in the blanks The reverse of a string x, denoted rev(x), is the string obtained by writing x backwards. For example, if x = abbaaab then rev(x) = baaabba. If A is a subset of Σ*, the reverse of A, denoted rev(A), is the subset of Σ* consisting of all reverses of strings in A: rev(A)={rev(x) | x∈A} For example, rev({a,ab,aab}) = {a,ba,baa}. Suppose you are given a deterministic finite automaton M accepting a set A. Show how to construct a DFA N accepting rev(A). (Kozen would suggest putting pebbles on the final states of M and moving them backwards along transition edges.) Describe N formally (i.e. in terms of Q, δ, etc.) including the definition of acceptance. Hint: the subset construction will be helpful here. You can start with M = (Q, Σ, δ, s, F) and define the components of N in terms of the components of M. 1. DFA N = (Q_N, Σ, δ_N, s_N, F_N) where Q_N = ___ 2. DFA N = (Q_N, Σ, δ_N, s_N, F_N) where δ_N = ___ 3. DFA N = (Q_N, Σ, δ_N, s_N, F_N)…arrow_forward
 Database System ConceptsComputer ScienceISBN:9780078022159Author:Abraham Silberschatz Professor, Henry F. Korth, S. SudarshanPublisher:McGraw-Hill Education
Database System ConceptsComputer ScienceISBN:9780078022159Author:Abraham Silberschatz Professor, Henry F. Korth, S. SudarshanPublisher:McGraw-Hill Education Starting Out with Python (4th Edition)Computer ScienceISBN:9780134444321Author:Tony GaddisPublisher:PEARSON
Starting Out with Python (4th Edition)Computer ScienceISBN:9780134444321Author:Tony GaddisPublisher:PEARSON Digital Fundamentals (11th Edition)Computer ScienceISBN:9780132737968Author:Thomas L. FloydPublisher:PEARSON
Digital Fundamentals (11th Edition)Computer ScienceISBN:9780132737968Author:Thomas L. FloydPublisher:PEARSON C How to Program (8th Edition)Computer ScienceISBN:9780133976892Author:Paul J. Deitel, Harvey DeitelPublisher:PEARSON
C How to Program (8th Edition)Computer ScienceISBN:9780133976892Author:Paul J. Deitel, Harvey DeitelPublisher:PEARSON Database Systems: Design, Implementation, & Manag...Computer ScienceISBN:9781337627900Author:Carlos Coronel, Steven MorrisPublisher:Cengage Learning
Database Systems: Design, Implementation, & Manag...Computer ScienceISBN:9781337627900Author:Carlos Coronel, Steven MorrisPublisher:Cengage Learning Programmable Logic ControllersComputer ScienceISBN:9780073373843Author:Frank D. PetruzellaPublisher:McGraw-Hill Education
Programmable Logic ControllersComputer ScienceISBN:9780073373843Author:Frank D. PetruzellaPublisher:McGraw-Hill Education